
tg-me.com/knowledge_accumulator/269
Last Update:
Compositional Regularization: Unexpected Obstacles In Enhancing Neural Network Generalization [2025]
Во многих соседних каналах писали про сенсацию - первая сгенерированная статья от AI Scientist прошла Peer Review на ICLR. Но вот что грустно - коллеги-авторы не осмеливаются рассказать про, собственно, саму статью.
Возьму эту задачу на себя. Но это не совсем обзор, скорее, пересказ статьи от лица автора, с сохранением формулировок. Отсебятины в пересказе нет.
Итак, рассмотрим понятие Compositional Generalization. Под ним подразумевается способность собирать новые комбинации из уже существующих компонент. Это мощнейший способ решать новые проблемы, и люди постоянно это используют.
Несмотря на успех нейросетей в целом, модели не всегда хорошо с такой генерализацией справляются. В данной статье для улучшения ситуации предлагается ввести явный Compositional Regularization.
Он будет штрафовать за отклонения от ожидаемых композиционных структур во внутренних представлениях нейросети с целью простимулировать модель формировать композиционные представления.
Итак, рассмотрим LSTM [модель из 2016 за авторством Ian Goodfellow]. В ней есть скрытое состояние h_t. Compositional Regularization считается как сумма L2-расстояний между каждыми двумя соседними h_{t} и h_{t+1}.
Она добавляется к обычному лоссу с каким-то весом и нужна для подталкивания модели к формированию аддитивных представлений, что является простейший формой композиционности.
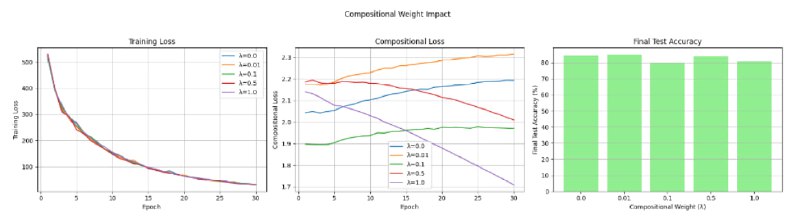
Для экспериментов рассмотрим задачу подсчёта записанных в виде текста арифметических выражений, например, "3+4" или "7*2". Будем обучать LSTM на датасете из 1000 таких выражений и тестировать на отложенной выборке из 200.
Бейзлайн показывает 84% точности на тестовом датасете. Мы проверили профит нашей композиционной регуляризации. Перебрав разные значения её веса, мы обнаружили, что точность на тестовом датасете не увеличивается ни при каком значении этого веса. При этом, у нас получается уменьшить сам этот композиционный лосс. При увеличении веса добавки в какой-то момент точность на тесте падает.
Это показывает, что несмотря на то, что композиционная регуляризация стимулирует обучение композиционных представлений, это может конфликовать с основной функцией ошибки.
Во второй серии экспериментов мы проверяли модель на датасете из более сложных арифметических выражений, и в нём обе модели - без регуляризации и с ней - показали сильно более плохой результат. Эти результаты наталкивают на мысль о том, что одной такой регуляризации может быть недостаточно для решения проблем, создаваемых сложными композиционными структурами.
Хоть в данной работе у нас и не получилось добиться положительного результата с помощью такой регуляризации, на будущее мы предлагаем исследовать другие регуляризации, попробовать переопределить композиционность в контексте нейросетей, а также проводить тесты на более сложных данных.
==== Пересказ закончен ====
Хоть я и удивлён, что авторы из sakana.ai вообще не постыдились это всё опубликовать и похвастаться перед миром, очень рад, что у человечества появились инструменты для генерации таких работ. Вся система так называемых "научных конференций" - это рак в теле технологического прогресса, и чем быстрее они все загнутся под тяжестью вот такого вот говна, тем лучше.
Впрочем, они уже отчасти загнулись под тяжестью сгенерированного людьми говна, но отменять их никто не собирается - это отличный способ имитировать деятельность для начальников в пиджаках. Но теперь наблюдать за этим станет ещё интереснее.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/269